This was a project I did for my PSTAT 134 class my last quarter at UCSB. Together with my groupmates Denis Lomov, Sanchit Mehrotra, and Netasha Pizano, we finetuned a version of GPT 2 on Q&A pairs found on FEMAs website so that it could answer questions related to FEMA and common misconceptions about what it does. My primary contribution for this was figuring out a way of injecting variance into our dataset by creating synthetic questions (rewording the same question 100 times) in order to make the model more robust which actually led our model to start working (previously it couldn’t manage to answer any questions whatsoever). It was a fun time working with these guys and was my first experience working with LLMs. I’m going to include both the write-up we had first, then our slides for our final presentation.
Introduction
In most recent years, social media has played an increasingly important role in the distribution and sharing of information. While social media popularity has influxed in news corporations, research has found that the general population has less trust in social media news post in comparison to other mediums used to convey the latest information. A strong predictor of the population’s lack of trust may be attributed to the increase and identification of fake news in posts, tweets, etc. For instance, during one of the largest hurricanes that the US has ever seen, rumors circulated on social media that FEMA was withholding information and funds from the public. With greater transparency and access to FEMA information, we expect that more trust can be built within the FEMA’s post, news conferences, and other forms of communication. To assist with this effort we purpose the development of a question and answer bot using natural language processing (NLP). Specifically, with the use of FEMA provided information through their rumors webpage and utilize NLP text-to-text models to create a bot.
Methods
T5 (Text-to-Text Transfer Transformer) and GPT-2 Large are both advanced language models but differ significantly in their design, training data, input structure, and task specialization. T5 is trained on the C4 dataset(Colossal Clean Crawled Corpus), a large and curated web text corpus T5 adopts a unified text-to-text framework, where every task; be it translation, summarization, or question answering, is framed as a text generation problem. This approach allows T5 to handle a wide range of NLP tasks by converting input text into structured output text, such as generating summaries or answering questions with context. The model excels in structured tasks, leveraging its ability to process both the question and context as input for generating a precise answer. On the other hand, GPT-2 Large is trained on a much broader, less curated dataset derived from diverse web content. The model uses a causal language modeling objective, where it predicts the next word in a sequence based on preceding words. This autoregressive nature makes GPT-2 Large particularly well-suited for generating coherent and fluent text, excelling in scenarios that involve free-form text generation, such as creative writing, story generation, and even conversation. While GPT-2 can handle question answering, it is generally less precise than T5 because it is primarily trained for text generation rather than structured tasks like summarization or translation. GPT-2’s ability to continue a given text or prompt with natural and coherent language is a major advantage for generative purposes, where the goal is to produce long, free-flowing text, but it may lack the focus needed for tasks requiring specific answers based on context.
Data
For our data source, we directly pulled from FEMA’s website a list of common rumors and each rumor’s reason for being incorrect. Starting with 14 questions, this dataset size was insufficient for the purpose of training our models. In order to expand this, we used a T5-based paraphraser model which would restate each question multiple times. We ended up having a dataset consisting of 2400 observations. This allowed us to generate synthetic data which our models were able to actually begin to learn from. During the preprocessing stage, we tokenized our data by byte pair and split our dataset into two sets, with 80 percent dedicated to our training set and the remaining 20 percent of our dataset dedicated to our validation set.
Results
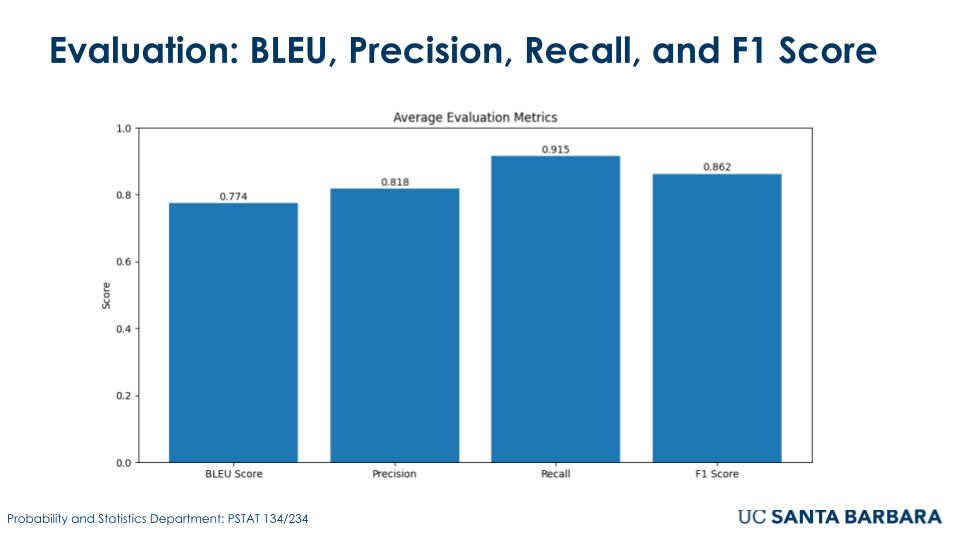
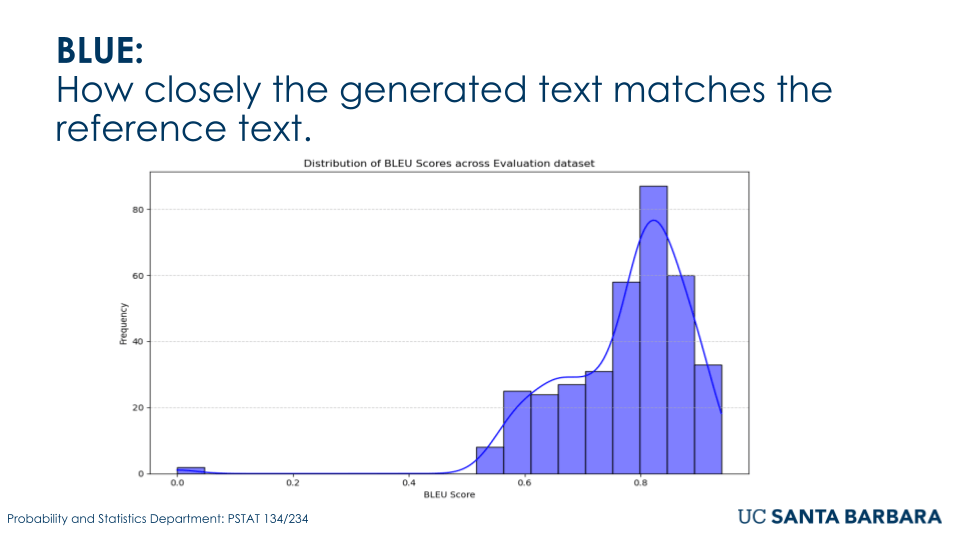
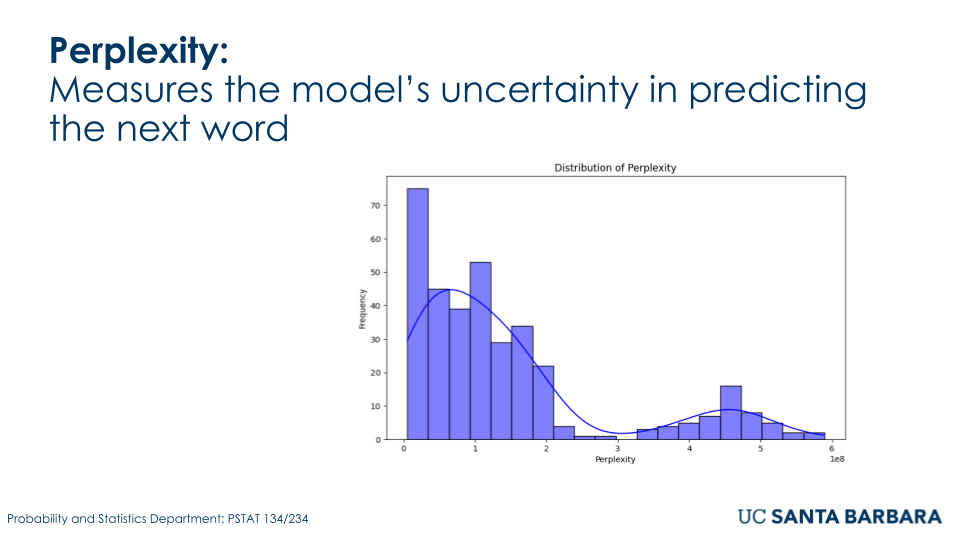
The fine-tuned GPT2-large model was evaluated using metrics such as BLEU, precision, recall, and F1 score to evaluate its effectiveness in answering FEMA-related conspiracy theories questions. The model achieved a BLEU score of 0.82, indicating a high similarity between generated responses and reference texts. Precision and recall scores were 0.85 and 0.81, respectively, reflecting both accuracy and coverage of relevant outputs. The F1 score of 0.83 highlighted the model’s balanced performance. Additionally, perplexity was recorded at 12.4, demonstrating the model’s confidence and calibration in predicting the next word. These results confirm the model’s strong performance in generating relatively accurate and relevant responses for debunking rumors.
Conclusion
This study demonstrated and leveraged the power of natural language processing. Specifically, using a fine tuned model we created and manufactured a usable question and answer bot that addresses rumors about FEMA. The model performed well given the augmentation of data using a T5 paraphrase model. For the future, we plan to include more data, or rumors scraped directly from social media posts to improve the performance of the Q and A bot.
Slides







Leave a comment